
Thomas Baudel(c)
Thèse de Doctorat en Informatique
sous la direction de Michel Beaudouin-Lafon
soutenue le 15 décembre 1995
à l'Université de Paris Sud
Software stands between the User and the Machine
Harlan D. Mills
Les différents prototypes présentés montrent la grande variété de modèles d'interaction concevables. Pour chacun de ces modèles, les aspects importants, les détails qui permettent une mise en oeuvre réussie sont de nature très différente : de l'intégration du modèle dans un environnement logiciel pour le cas d'Hypermarks à l'utilisation de gestes permettant une expression implicite de l'intention dans celui de Charade. Notre objectif est de fournir une synthèse permettant de concevoir de nouveaux modèles d'interaction, plus adaptés aux fonctionnalités de nouvelles applications ou tirant un meilleur parti des possibilités de l'utilisateur, en particulier pour des tâches créatives. Pour cela, nous proposons une démarche générale de conception. Cette démarche se concentre essentiellement sur l'analyse des entrées du système (nimbus) et ne traite de l'aspect présentation d'information et rétroaction que lorsque qu'il est nécessaire pour décrire le modèle d'interaction dans sa globalité. Cette démarche ne se prétend pas non plus génératrice : elle ne permet pas de produire un modèle d'interaction pour toute application donnée. Nous présentons tout d'abord une vision d'ensemble, puis nous proposons certaines règles qui régissent la conception de l'axe paradigmatique de l'interaction, ainsi que des implications sur l'architecture logicielle des modèles d'interaction.
Nous ne saurions proposer une méthode formelle inspirée de notre démarche à l'heure actuelle : nous souhaitons nous limiter à la pose de quelques balises permettant de mieux comprendre et représenter ce qu'est un modèle d'interaction. Comme nous l'avons précisé en introduction, la mise au point d'un outil formel dépasse le cadre de notre étude.
Figure VII.1.1 : les trois composantes du nimbus d'un système interactif
Sur un clavier, les actions élémentaires sont les enfoncements de touches détectés par le système, lorsque l'appui sur une touche est suffisamment important pour déclencher l'interruption. Pour le système, il n'y a pas de touches à demi-enfoncées, ou "en cours d'enfoncement", donc l'appui sur une touche est une action ininterruptible.
Dans le cas des dispositifs à entrée continue, les suites de changements d'états sont des échantillons d'une trajectoire continue. Une action élémentaire est une portion de trajectoire reconstituée à partir de l'échantillonnage. On ne peut considérer chaque point de la trajectoire comme une action élémentaire : chaque point échantillonné est une partie de l'action de tracé qu'a réalisé l'utilisateur en un seul geste conscient et ininterruptible. La segmentation consiste à analyser une entrée continue pour en extraire ses actions élémentaires. La segmentation n'est pas un procédé systématique et totalement fiable, ce qui impose une limite à notre capacité de décrire précisément un modèle d'interaction. La notion d'actions séparables et d'actions intégrales que nous définirons ultérieurement nous aidera à définir les actions élémentaires plus précisément dans le cas de l'entrée continue et de la multimodalité.
On définit l'ensemble A des actions élémentaires effectuables par l'utilisateur sur tout dispositif capteur du système interactif. Cet ensemble A est un sous-ensemble de l'espace perceptuel (nimbus) du système interactif : il ne présente que les portions de cet espace que l'utilisateur peut effectivement atteindre intentionnellement et sans effort excessif. Par exemple, dans Charade, nous avons choisi de discrétiser les configurations possibles de la main afin de permettre à l'utilisateur de produire sans effort toute posture requise pour l'interaction. Pour définir A, il convient de déterminer un choix de dispositifs effecteurs et leur mode d'actionnement : quels organes moteurs de l'utilisateur les actionnera.
On distingue ensuite dans A un sous-ensemble Ai des actions considérées comme connues ou intuitives pour l'utilisateur du système ciblé. Les actions connues sont celles réalisées par l'utilisateur dans des tâches similaires à la tâche informatisée, ou liées à celles-ci par le biais d'un trope (par exemple une métaphore ou une synecdoque). Les actions dites intuitives peuvent être assimilées aux "intuits" (affordances) définies par J. Gibson [Gibson 1979] et appliquées à un contexte informatique par W. Gaver [Gaver 1991]. Le critère de naturel d'une interface sera donc en grande partie déterminé par le choix de l'ensemble Ai. Dans le cas de Charade, le choix de Ai a été déterminé en choisissant des postures correspondant à des gestes usuels (déplacement, retour...), et en étendant ce choix par composition de gestes simples et l'introduction limitée de postures plus complexes, uniquement dans le cadre d'une utilisation du système plus poussée.
Comme nous l'avons déjà précisé, afin de respecter le critère de concision, ce langage se doit d'être constitué de phrases aussi courtes que possible. Dans le cas de la manipulation directe et tous les modèle d'interaction que nous avons conçus, ce langage est effectivement pratiquement réduit à l'ensemble des singletons du monoïde : toute phrase signifiante pour le système est une simple action de l'utilisateur. La présence de modes est certes indispensable, car les dispositifs en usage actuellement sont versatiles et doivent s'adapter à plusieurs contextes d'utilisation et outils informatiques. Le même dispositif de pointage peut être utilisé pour la navigation hypertexte, le dessin direct ou la manipulation de cellules d'un tableur. Il est cependant possible de limiter les modes à des changements de contexte importants, ou à des micro-modes dans lesquels la successions des entrées est assimilable à une seule action élémentaire de l'utilisateur. Nous ne nous étendrons pas sur la description des langages possibles à partir d'un vocabulaire d'actions élémentaires défini : des outils connus tels que UAN [Hartson, et al. 1990] satisfont nos besoins de description.
La possibilité de définir S dépend évidemment de la puissance d'expression de L(Ai) et du modèle conceptuel : il n'est pas toujours possible d'établir une sémantique entre tout langage et tout modèle conceptuel. Par exemple, le modèle d'interaction de Ligne Claire est spécialisé pour un certain type de modèle conceptuel, dans lequel les objets principaux sont des dessins composés de courbes splines. Certains modèles d'interaction comme les interfaces à base de lignes de commandes, les menus et écrans de saisies ou les toolglass sont complets, c'est-à-dire qu'il est toujours possible de construire une sémantique entre un modèle conceptuel et le langage engendré par les actions élémentaires.
Cependant, le modèle d'interaction peut être complet sans être efficace pour autant. Il est possible que certaines actions ne puissent être définies par un choix d'actions naturelles ou requièrent des phrases du langage complexes et longues. Par exemple le modèle d'interaction des lignes de commandes est peu adapté au dessin. On qualifiera un modèle d'interaction de direct lorsque la relation S est une bijection entre C et Ai, c'est à dire que le langage L(Ai) est réduit à l'ensemble des singletons et que S est totalement conforme. À l'heure actuelle, les seuls modèles d'interaction directs sont limités à des applications simples, comme les automates distributeurs de billets de transport pour un nombre limité de destination (Chapitre II.1.5), certaines interfaces de consultation de bases de données simples ou la navigation dans des hypertextes limités.
Dans l'état actuel de nos connaissances, nous ne savons pas réaliser un modèle d'interaction à la fois complet et direct. Nous ne pouvons que proposer des améliorations sur des modèles existants pour se rapprocher de l'un ou de l'autre des objectifs. Aussi, nous préférons nous concentrer sur la réalisation de modèles d'interaction adaptés à certains modèles conceptuels particuliers, en rendant le modèle le plus direct possible.
Pour cela, nous étudions tout d'abord comment définir A et Ai pour les élargir en préservant une interaction naturelle. Cette exploration de l'axe paradigmatique nous permettra d'élargir l'espace d'arrivée de la relation S (considérée comme une application S: C->Ai) et de trouver les meilleures images possibles pour les objets de C dans Ai. Nous étudions ensuite comment définir C et S pour représenter un modèle conceptuel et évaluer la conformité de la relation de sémantique. On remarquera que nous ne nous étendons pas sur l'axe syntagmatique : tout d'abord celui-ci est largement étudié par ailleurs, ensuite, nous avons vu que plus celui-ci pouvait être limité, plus l'interaction est concise et directe.
La limite essentielle de cette classification est l'absence de prise en considération de caractères pragmatiques liées aux capacités motrices et articulatoires du corps humain. Ainsi, des dispositifs comme la souris ou le stylet d'une tablette graphique utilisé en mode relatif sont représentés par la même image dans l'espace de conception défini par Card, Robertson et Mackinlay. Il existe pourtant des différences entre ces dispositifs : la souris est moins maniable que le stylet et offre une moins grande précision. Choisir une description du vocabulaire de base en termes de signaux captés par le système se révèle donc insuffisant, en particulier dans la définition des interfaces gestuelles. Il doit être possible de distinguer plusieurs types d'entrée différents pour l'utilisateur produisant les mêmes signaux interprétés par le système. Enfin, il importe que la description des éléments atomiques de l'interaction permettent d'analyser et de détecter des cas où un signal détectable par le système n'est dans la pratique pas réalisable par l'utilisateur : certains progiciels proposent par exemple des séquences de touches de contrôle particulièrement difficiles à effectuer sur un clavier : la combinaison de modifieurs distants (Controle-Majuscule-Option + F1) et de touches (enter) requiert une dextérité hors du commun.
Dans le cas des interfaces gestuelles pures il est cependant possible de créer un ensemble d'atomes de base permettant de décrire les actions de l'utilisateur de façon complète. Le système reconstituant les gestes de l'utilisateur à partir des informations des capteurs, puis les interprétant, il n'existe pas de découplage entre les capacités d'action de l'utilisateur et ce qu'en perçoit le système : les éléments de base de l'interaction sont effectivement les gestes de l'utilisateur. Cependant, nous avons vu que ces interfaces n'étaient pas adaptées à toutes les tâches : la précision de la main libre est insuffisante pour autoriser un contrôle fin des objets de l'interaction. Nous en retenons cependant la tentation d'identifier un alphabet élémentaire de l'interaction en analysant les mouvements effectifs de l'utilisateur : l'activation de chacun de ses muscles et articulations dans un modèle physiologique de l'interaction.
En tout état de cause, ce modèle serait malgré tout insuffisant et inadapté : les gestes décrits ne permettent pas d'en déduire aisément les signaux induits sur des dispositifs capteurs du système, et donc de construire un programme susceptible de les interpréter. Cette description serait inutilement précise lorsque des dispositifs effecteurs intermédiaires sont utilisés : il serait particulièrement malcommode de devoir décrire une interface gestuelle utilisant un stylet et une tablette graphique en modélisant les mouvements des doigts et du poignet tenant le stylet. Un utilisateur peut en fonction du contexte et de sa morphologie être amené à tenir le stylet d'une façon différente qu'il n'est pas possible de prédire. Les touches du clavier ne sont pas toujours frappées avec les mêmes doigts, même par les dactylographes confirmés, lorsqu'ils ne sont pas en phase d'entrée de texte intensive. Enfin, les utilisateurs handicapés ne pourraient être pris en compte dans la description du modèle d'interaction.
Notre méthode de définition des actions de base utilisera donc les mêmes compromis de description : nous choisissons de décrire les éléments de l'interaction par les signaux élémentaires captés par le système informatique (nimbus ou espace perceptuel du système). Cependant, nous nous devons d'ajouter des indications sur la gestuelle imposée ou conseillée pour activer les dispositifs, lorsque celle-ci est utile (aura de l'utilisateur).
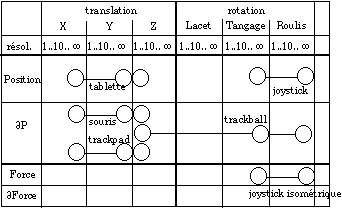
Le tableau défini par Card, Mackinlay et Robertson [Card, et al. 1991], présenté au chapitre II.4.2 et sur la figure VII.2.1, permet de placer les dispositifs d'entrées en fonction des dimensions qu'ils capturent.
Figure
VII.2.1 : positionnement de dispositifs d'entrée en fonction des
dimensions qu'ils permettent de capturer, de la nature de l'impulsion
l'actionnant (positionnement, déplacement, force ou pression
exercée) et de sa résolution dans chacune des dimensions.
Ce positionnement des caractéristiques d'un dispositif permet :
* de repérer le nombre et le type des informations qui peuvent être émis par les différents dispositifs, et de comparer différents dispositifs a priori équivalents. Par exemple, les différents dispositifs de pointage présentés dans la figure VII.2.1 sont utilisés de façon interchangeable et considérés comme fonctionnellement identiques. On remarque pourtant qu'ils n'occupent pas les mêmes positions du tableau. On en déduit que certains de ces dispositifs seront plus adaptés à certaines tâches que d'autres. De fait, il est reconnu que la tablette est plus adaptée à la spécification de positions que la souris [Mackenzie, et al. 1991], qui est elle-même plus adaptée que le trackball. Le joystick est cependant le dispositif de choix dans de nombreux jeux électroniques où la tâche consiste à diriger un vaisseau : les dimensions de rotations (tangage et roulis) sont plus adaptées pour spécifier les valeurs des variables contrôlées par l'application, à savoir la hauteur et la direction prises par le vaisseau. Il convient de noter que d'autres facteurs peuvent également entrer en jeu dans le choix d'un dispositif. Par exemple, les organes moteurs humains mis en oeuvre pour contrôler le dispositifs ont aussi un rôle important : le stylet de la tablette graphique est contrôlé à l'aide des doigts et du poignet, tandis que la souris est essentiellement contrôlée par le poignet. Comme nous l'avons indiqué précédemment, la définition complète d'un modèle d'interaction requiert la prise en compte du système moteur et articulatoire humain.
* d'affecter les dimensions captées par les dispositifs à des attributs d'un modèle conceptuel. Lorsque le dispositif est complexe (gant numérique, par exemple), il est important de séparer chacune des dimensions afin d'analyser son rôle potentiel dans l'interaction. C'est ce que nous avons fait dans Charade, en choisissant tout d'abord de ne pas tenir compte des dimensions de positionnement absolu (x, y, z) puis de discrétiser et d'affecter les dimensions de rotation du poignet et de pliure des doigts à la segmentation des gestes.
* réciproquement, il est possible de considérer un certain nombre de variables contraintes d'un modèle conceptuel (attributs d'un ou plusieurs objets) et de chercher le dispositif ou l'ensemble de dispositifs le plus adapté (potentiellement) à une tâche d'édition d'objet aux caractéristiques connues. Par exemple, Card, Mackinlay et Robertson soulignent à l'issue de leur analyse que des dispositifs de pointage plus adaptés que le trackball ou la souris doivent pouvoir être créés. Leur remarque provient de la constatation 1) que les doigts sont un organe au contrôle moteur plus fin que le poignet, utilisé pour la souris 2) qu'un dispositif à deux dimensions de déplacement relatif (X et Y sur notre schéma) est plus adapté à une tâche de pointage d'un objet sur une surface en deux dimensions que le trackball, qui fournit deux dimensions de rotation (tangage et roulis). Quelques temps après la parution de l'article, Apple a proposé sur sa gamme d'ordinateurs portables le Trackpad, qui se révèle effectivement plus adapté que le trackball. La souris demeure cependant toujours préférée au Trackpad, car la configuration de ce dernier, tout comme le trackball, n'autorise que difficilement la manipulation conjointe du bouton et le déplacement du pointeur. Il reste donc à créer un dispositif reprenant le concept du Trackpad, mais permettant un contrôle du bouton avec le pouce de la main dominante plus aisé.
Cependant, comme nous l'avons déjà évoqué, le tableau VII.2.1 ne permet pas de positionner un dispositif capturant des dimensions non indépendantes, comme le cube modelable [Murakami et Nakajima 1994] (paragraphe II.4.2). Le modèle utilisé pour relier les dimensions captées à des attributs du modèle conceptuel consiste à définir non pas une série de variables indépendantes, mais une surface continue en trois dimensions, appelée le volume de contrôle (figure VII.2.2). Les contraintes géométriques du volume de contrôle (continûment déformable, topologie invariante) permettent de représenter les interdépendances entre les signaux captés par le dispositif, qui ne sont pas explicitées par la présentation du tableau. Les déformations du cube ne sont pas reliés directement à des attributs du modèle conceptuel, mais à un volume de contrôle. Les attributs (décrit par Murakami et Nakajima comme la "forme objective" (objective shape)) sont reliés à des points de contrôle de ce volume. Le contrôle des objets est donc indirect, sauf si le volume de contrôle correspond en tous points à la forme objective des objets manipulés. L'un des objectifs des auteurs est effectivement de réaliser un cube modelable réactif permettant d'adapter la forme du cube modelable en fonction de l'objet en trois dimension à manipuler.

Figure VII.2.2 : association d'un volume de contrôle au cube modelable
de [Murakami et Nakajima 1994].
L'ajout d'un volume de contrôle permettant de spécifier les contraintes entre dimensions captées par les dispositifs nous permet d'affiner l'espace de description des dispositifs en prenant en compte les relations pouvant exister entre les différents axes d'un ou plusieurs périphériques d'entrée.
Le placement d'un dispositif dans ce tableau, ou au contraire la recherche d'un dispositif permettant le meilleur contrôle possible d'un ensemble connu de variables liées est la première étape de la définition des actions élémentaires d'un modèle d'interaction. Cette étape requiert déjà une certaine connaissance du type des variables et des structures informationnelles que permet de manipuler le modèle d'interaction. Cependant, dans la plupart des cas, il est possible de se contenter de dispositifs standards relativement simples, tels qu'un clavier et un dispositif de pointage.
Par exemple, le déplacement d'une souris sur un plan fournit un échantillonnage en deux dimensions : les variations de l'ordonnée et de l'abscisse du curseur. Ces deux signaux sont indissociables et se composent donc spatialement. Tout déplacement de la souris forme une action élémentaire constituée de deux signaux perçus. Un déplacement est une trajectoire. Lorsque seuls les points de départ et d'arrivée de la trajectoire sont connus et interprétés par le système, chaque déplacement est une action élémentaire. Si la dynamique de la trajectoire est analysée et prise en compte par le système, alors l'action élémentaire est constituée de la suite (temporelle) des points échantillonnés par le dispositif.
Lorsque le modèle d'interaction n'utilise que des changements d'états discrets des dispositifs, les action élémentaires sont constituées uniquement de signaux simples ou de compositions spatiales de signaux (par exemple le "shift clic", ou l'appui simultané sur plusieurs touches dans certains jeux vidéo). En revanche dans l'interaction gestuelle, les actions élémentaires sont définies par l'algorithme de segmentation utilisé. Il est donc possible de considérer la même suite de signaux comme une action élémentaire ou non, suivant l'algorithme choisi et l'utilisation qui est faite des actions élémentaires. La définition des actions élémentaires devant être perceptible pour l'utilisateur, l'algorithme de segmentation se doit de découper une trajectoire continue en actions élémentaires aisément identifiables pour l'utilisateur et donc correspondant à sa perception de l'environnement. C'est pourquoi l'algorithme de segmentation de Charade discrétise les postures reconnues, afin de permettre à l'utilisateur de les adopter aisément. La segmentation par l'utilisation d'un dispositif déclencheur (le bouton de la souris ou la pointe du stylet dans les interfaces à base de reconnaissance de marques) permet également à l'utilisateur de se constituer un modèle de la façon dont est réalisée la segmentation.
De la même façon, des signaux simultanés seront considérés comme faisant partie de la même action élémentaire s'ils concourent pour agir sur un objet perçu identique. R. Jacob [Jacob, et al. 1994] définit les notions d'action intégrale et d'action séparable : lorsque les attributs contrôlés par des dispositifs séparés concourent à la manipulation d'une même structure perceptuelle, alors les attributs contrôlés sont reliés de façon intégrale. En revanche, si les attributs contrôlés sont considérés par l'utilisateur comme distincts, alors ces attributs sont qualifiés de séparables. À titre d'exemple, R. Jacob [Jacob et Sibert 1992] étudie deux tâches, l'une intégrale (figure VII.2.3) et l'autre séparable (figure VII.2.4).
Ces études menées avec différents dispositifs d'entrée ont montré qu'un dispositif (en l'occurrence un Polhemus, dispositif à 6 degrés de libertés indépendants contrôlables en parallèle) permettant de manipuler en une seule action élémentaire intégrale les attributs intégralement liés était plus efficace qu'un dispositif (une souris, permettant d'ajuster la position, puis la taille du rectangle) obligeant à séparer artificiellement les attributs. Réciproquement, dans la tâche séparable, le Polhemus s'est avéré significativement moins efficace que la souris.
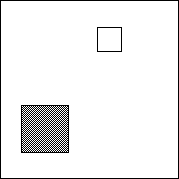
Figure
VII.2.3 : exemple de tâche intégrale. L'objectif est d'ajuster la
position
(deux dimensions) et la taille (une dimension intégralement
liée aux deux premières)
du rectangle gris pour les faire
correspondre avec celles du rectangle de bordure noire.

Figure
VII.2.4 : exemple de tâche séparable : L'objectif est de faire
correspondre
la position des deux rectangles et d'ajuster conjointement la
couleur du cercle noir avec
celle du rectangle gris l'entourant (une
dimension séparable des deux premières).
Ainsi il est possible de distinguer des actions menées en parallèle en fonction de la séparabilité des attributs contrôlés. Si les attributs contrôlés sont intégralement liés, les signaux captés en parallèle constituent une suite d'une même action élémentaire (multimodalité actionnelle synergique). En revanche, si les attributs sont séparables, il convient de distinguer deux actions élémentaires distinctes effectuées en parallèle.
En résumé, il est possible de constituer des actions élémentaires par conjonction spatiale et temporelle de signaux captés. Les critères permettant de regrouper des suites de signaux captés sont l'ininterruptibilité pour la conjonction temporelle et l'intégralité des attributs contrôlés pour la conjonction spatiale.
Par exemple, on considérera qu'une marque de correction contrôlant à la fois la position et l'épaisseur d'un trait dans Ligne Claire est une action élémentaire : il n'est pas possible de s'interrompre au milieu d'une action et de la reprendre sans changer le sens de l'action initiale, car la marque de correction s'interprète de façon indivisible. Inversement, lors du tracé d'une ligne en plusieurs couleurs dans VoicePaint [Gourdol, et al. 1992], les actions de tracés peuvent être interrompues par des commandes vocales du type "rouge", "bleu", "plus épais" ou "plus fin". Dans ce cas, on considérera que les actions élémentaires ne sont pas un tracé complet (de l'enfoncement du bouton de la souris à son relâchement), mais les déplacements non interrompus par des commandes vocales de l'utilisateur. En effet, les attributs de trace et de changement de couleur ou d'épaisseur discrets ne sont pas reliés de façon intégrale, mais peuvent être considérés séparément. Si l'épaisseur du trait était liée à la pression du stylet, comme le permettent les tablettes graphiques actuelles, alors l'attribut d'épaisseur serait intégralement lié aux attributs de position et les actions élémentaires seraient des traces complètes.
Dans le cas des toolglass, on peut considérer que l'action de "clic à travers" est intégrale car les deux mains concourent vers un point commun pour superposer le pointeur, l'outil choisi et l'objet sur lequel on désire effectuer une opération. Au contraire, dans une tâche d'édition de texte où la main gauche effectue la navigation tandis que la main droite réalise les corrections sur le texte [Buxton et Myers 1986], les deux actions sont séparables. Cette constatation est d'ailleurs mesurable, puisque les études réalisées sur ces deux méthodes d'interaction montrent que dans le premier cas, la toolglass et le pointeur sont actionnés en parallèle [Kabbash, et al. 1994], tandis que dans le second, l'entrelacement des mouvements main dominante/main non dominante est beaucoup moins présent.
Cette distinction entre actions intégrales et séparables est toutefois schématique : en fait il existe un continuum entre les deux notions qu'il conviendrait d'expliciter. Dans la plupart des techniques d'interaction actuelles, les actions élémentaires sont des signaux uniques et non composés (à part l'emploi de touches modificatrices du clavier : Majuscule, Contrôle, Alt...). Une telle distinction n'est utile que lorsque les objets à contrôler sont complexes. Il convient alors d'analyser les structures perçues par l'utilisateur afin de choisir des actions élémentaires adaptées en fonction de la séparabilité des attributs à manipuler.
* arrangement spatial des dispositifs (contraintes articulatoires statiques) : une action élémentaire ne peut être réalisé par l'utilisateur car l'emplacement des dispositifs ne permet pas au organes moteurs humain de les actionner convenablement. Word 3 pour Macintosh, en 1989, était renommé pour la difficulté d'utilisation des raccourcis claviers qu'il proposait. Par exemple, une commande était déclenchables par la combinaison "Commande-Option-Majuscule-X", qui mettait tous les doigts de la main gauche à contribution dans une position inconfortable. Suivant la disposition du clavier (notamment le passage du Qwerty à l'Azerty) certaines combinaisons de touches peuvent être particulièrement difficiles, voire impossible, à réaliser. Il convient pour résoudre ces difficultés de grouper les dispositifs employés afin de permettre une utilisation adaptée des combinaisons d'actions. Par exemple, le clavier de piano, fruit d'une longue succession d'améliorations, se révèle particulièrement adapté au jeu musical occidental reposant sur la gamme tempérée et l'harmonie classique.
* contraintes motrices : certaines actions peuvent requérir une expertise et un contrôle moteur trop fin pour l'organe moteur sensé les actionner. On peut supposer par exemple qu'il serait difficile d'actionner une souris avec le pied, ou d'utiliser une interaction à base de reconnaissance de marques avec la main gauche : le contrôle moteur requis pour ces techniques d'interaction est trop fin pour permettre une utilisation par les organes ayant un mauvais contrôle moteur. Comme nous l'avons proposé au chapitre II.4.1, il est plus judicieux d'attribuer en priorité les dispositifs requérant un contrôle moteur fin (dispositifs à entrée continue) aux organes moteurs les plus performants et de n'utiliser les autres organes que pour des dispositifs à états discrets ou des capteurs d'états.
* contraintes articulatoires : lorsque nous avons décrit Charade, nous avons précisé que sur un total de 3584 postures reconnaissables par le système, seulement environ 300 étaient réalisables par un utilisateur type sans contorsions exagérées. Il est par exemple presque impossible de courber l'auriculaire sans courber l'annulaire. Il convient dans ce cas de ne pas inclure d'actions élémentaires posant des difficultés articulatoires dans l'ensemble des actions élémentaires constituant le vocabulaire de base du modèle d'interaction.
* production de signaux concurrents (multimodalité concurrente) : certains actionnements de groupes musculaires différents mais liés peuvent difficilement être réalisés de façon naturelle : il est par exemple difficile sans entraînement de battre deux rythmes différents, l'un ternaire, l'autre binaire, de chaque main. La production de signaux concurrents peut être effectuée au prix d'un certain entraînement, on ne peut donc la demander qu'à des utilisateurs experts.
La restriction d'un ensemble d'actions élémentaires à un sous-ensemble accessible à un utilisateur type, ou à un groupe d'utilisateurs ciblés (handicapés, par exemple) requiert une modélisation du système articulatoire et moteur humain. C'est pour permettre de prendre en compte ces contraintes qu'il importe de représenter dans un vocabulaire d'interaction des aspects externes au système proprement dit. Nous ne disposons cependant pas de description de ces contraintes de l'aura d'un agent humain nous permettant de les prendre en compte autrement qu'au cas par cas, en fonction des dispositifs et du modèle d'interaction choisis.
Un des objectifs que doit remplir la définition d'un vocabulaire d'actions de base est de rendre l'expression des modes et des paramètres implicites, contenus dans les actions élémentaires. Aussi l'une des tâches majeures du concepteur d'un modèle d'interaction est de fournir la possibilité de rendre les actions élémentaires porteuses de leur intentionnalité au lieu de requérir la fourniture d'un contexte (temporel) nécessaire à la détermination de l'objet d'intérêt.
W. Gaver [Gaver 1995],[Smerts, et al. 1994] propose en fait le même précepte pour la conception de techniques de représentation d'information, qu'il qualifie d'approche écologique de l'interaction.
Nous distinguons trois types d'actions intuitives : les actions connues de l'utilisateur cible ne supposent aucun apprentissage spécifique à l'application considérée : elles se déduisent de la pratique soit du domaine, soit du système informatique ; les extensions d'actions connues peuvent être déduites des actions connues et acquises par l'utilisateur, enfin les intuits ou invites ("affordances" en anglais) sont des actions induites naturellement par l'organisation de notre système moteur et son incidence sur notre perception de l'environnement. Un exemple d'intuit appliqué à l'informatique est le sens de défilement des scrollbars d'un éditeur : un clic dans la partie haute fait défiler le texte vers le bas, ramenant vers le début du texte.
Les guides de styles fournissent un environnement structurant pour l'utilisateur du système qu'il importe de préserver. Cependant, cette structuration gêne l'évolutivité vers des modèles d'interaction intégrateurs plus efficaces et généraux. L'un des obstacles majeurs à la généralisation des toolglass ou des interfaces gestuelles comme Hypermarks est la nécessite de préserver la compatibilité avec des vocabulaires d'actions définis pour être utilisés avec un matériel moins performant que le matériel actuel. La création de nouveaux modèles d'interaction est fortement handicapée par la nécessité de préserver la base installée et les automatismes acquis qui ne doivent pas être remis en question.
Les techniques d'interaction préconisées par les guides de styles ne sont pas complètes, mêmes pour la manipulation d'objets tel que le texte ou les listes d'objets. Par exemple un texte fortement structuré comme un rapport peu être édité avec un éditeur de plan, que proposent les traitement de textes actuels, ou un éditeur syntaxique comme Grif [Quint, et al. 1986]. Les règles définies par exemple pour la sélection de portions de textes sont dans ce cas insuffisamment précises, ou requièrent une adaptation des règles du modèle d'interaction intégrateur. Le concepteur de l'application doit dans ce cas préserver la compatibilité globale de son modèle d'interaction avec l'environnement, tout en offrant des mécanismes supplémentaires.
Lorsque les objets du modèle conceptuels sont plus complexes ou que leur présentation n'est pas définie par le modèle d'interaction intégrateur, il est toujours possible d'employer des actions connues de l'utilisateur, liées à la nature des objets du modèle conceptuel. Dans un logiciel de dessin ou Ligne Claire, par exemple, le tracé à main libre ou l'utilisation de la palette des couleurs reposent sur les techniques de dessin utilisées sur papier. L'interaction gestuelle permet souvent, comme nous l'avons vu, d'utiliser des actions connues dans de nombreuses manipulations d'objets informatiques : l'annotation et la mise en page de documents, le dessin de diagrammes ou la notation musicale...
Les commandes déclenchées par le clavier utilisent fréquemment l'initiale du nom de la commande (^I pour imprimer, ^O pour ouvrir, ^C pour copier, en anglais, ^B, ^I, ^U pour bold, italic, underline...). Lorsque le concepteur est à cours de mnémoniques simples, l'arrangement spatial des touches peut être utilisé comme palliatif : ainsi le menu "édition" utilise la rangée inférieure du clavier et reprend l'ordre d'apparition des éléments dans le menu (^X: couper, ^C: coller, ^V: coller, ^Z (sur un clavier qwerty) pour annuler).
L'utilisation d'actions symétriques ou antisymétriques permet également d'étendre le vocabulaire de l'interaction. Par exemple les outils de tracé de lignes, de rectangles et d'ellipses utilisent les mêmes actions de base. Les vocabulaires gestuels utilisés dans Charade et dans Hypermarks présentent également des symétries, comme la direction du geste pour passer à la page suivante ou au chapitre suivant, et des antisymétries comme la direction inverse pour revenir en arrière.
Enfin, des extensions limitées de la signification d'un geste (métonymies et synecdoques) ou l'emploi d'une métaphore permettent de proposer des actions que l'utilisateur peut acquérir sans apprentissage conscient. Ligne Claire propose une extension du modèle de dessin sur papier dans lequel les gestes de retouches ne laissent pas de traces sur le support, mais modifient les traits existants. La métaphore du bureau, utilisée par le finder du Macintosh, permet l'ajout de nombreuses fonctionnalités assez facilement : ainsi la possibilité d'imprimer un document en superposant les icônes du document et d'une imprimante disponible a-t-elle pu être ajoutée dans le système 7.5 d'une façon simple à comprendre pour l'utilisateur. Aaron Marcus [Marcus 1983] présente une application des tropes de la rhétorique classique à la conception de langages visuels et la représentation de l'information qui peut être étendue aux vocabulaires d'interaction.
Un "intuit" ou "invite" (affordances en anglais), concept défini par J. Gibson [Gibson 1979], est une caractéristique d'un objet dont la perception induit l'usage qui peut être fait de l'objet. Par exemple, la forme d'une poignée de porte induit à l'utilisateur son mode d'actionnement : une simple barre horizontale induira l'utilisateur à pousser la porte, tandis qu'une poignée en coude saillante induira la préhension et "invitera" la rotation qui permet le déverrouillage.
Appliqué à un contexte informatique, il est souvent possible de construire une méthode d'interaction naturelle à partir d'un représentation des objets mettant en valeur leur modes de fonctionnement, par la structuration globale de la présentation ou par l'utilisation d'attributs graphiques. Nous avons déjà présenté l'exemple de 4ème dimension (Chapitre I.2.3) qui offre une représentation graphique de schémas de bases de données par manipulation directe.
Comme autre exemple de l'utilisation d'intuits, S. Houde [Houde 1992] propose une technique de manipulation d'objets en trois dimensions utilisant des poignées de sélection. Ces poignées sont disposées sur l'objet de façon à permettre une identification immédiate de leur fonction (Figure VII.2.5).
 Figure
VII.2.5 : Utilisation de poignées de sélection pour la
manipulation d'objets en trois dimensions. La disposition des poignées
et la forme des curseurs induisent l'opération qu'ils permettent
d'effectuer.
Figure
VII.2.5 : Utilisation de poignées de sélection pour la
manipulation d'objets en trois dimensions. La disposition des poignées
et la forme des curseurs induisent l'opération qu'ils permettent
d'effectuer.
Nous ne saurions proposer de méthode générale de résolution de ces conflits, tout au plus fournir un exemple de solution employée : HyperCard et le Finder du Macintosh utilisent tous deux un modèle iconique permettant de représenter une hiérarchie de fichiers. Cependant les icônes du Finder s'appliquent par double-clic tandis qu'un simple clic est suffisant dans HyperCard. Pour distinguer les différences d'usage, Apple suggère dans une note technique une représentation différente des icônes, plus proche de celle des boutons que des icônes du finder [Apple 1990]. Ainsi, le choix d'une présentation différente par certains détails permet d'induire les différences de fonctionnement par rapport au comportement "standard" des objets.
Le système TicTacToon [Fekete, et al. 1995], destiné à des dessinateurs de dessin animés professionnels, utilise une tablette graphique et un modèle de dessin direct similaire à celui de Ligne Claire (sans les fonctions de retouche locale). L'une des principales préoccupations à l'heure actuelle des concepteurs est de trouver une tablette graphique ayant un "toucher" adéquat : la surface de plastique des tablettes actuelles est trop glissante, et si l'on remplace cette surface par une feuille de papier, le trait devient trop rêche, car la pointe du stylet n'est pas lubrifiée par de l'encre et ne glisse donc pas assez bien.
Dans Charade, la fatigue est un problème important, il convient de ne pas proposer une utilisation intensive de vocabulaires gestuels purs : les mouvements de la main dans l'espace font travailler tout le bras, qui se fatigue donc vite sans entraînement.
Le logiciel remplace une caisse enregistreuse et permet d'automatiser la comptabilité et d'effectuer un grand nombre de statistiques sur les opérations effectuées. Nous proposions dans la première version un écran de saisie standard, conçu pour permettre une saisie simple et rapide des fiches de caisse (Figure VII.2.6). Dans cet écran, des menus et listes de choix viennent guider la saisie de l'utilisateur, qui n'a besoin que de taper les premières lettres de chaque zone de saisie, le système établissant lui même la complétion.
Utilisé lors d'une première journée de formation, en dehors du cadre de travail, cette méthode de saisie fonctionnait correctement.

Figure VII.2.6 : Écran de saisie original
Cependant, replacé dans un contexte de travail, la saisie de la fiche de caisse devient une opération marginale au regard du maintien de bonnes relations commerciales et humaines avec les clients. Il en résulte que les utilisateurs n'ont pas leur attention portée sur le système et réalisaient d'importantes erreurs de saisies. Ces erreurs étaient la plupart du temps dues au choix de types de services différents de ceux effectués, les utilisateurs s'assurant cependant que le montant total de la fiche de caisse soit correct. Ainsi, les statistiques se trouvaient faussées sans que la comptabilité le soit. Il s'est avéré que l'on ne pouvait exiger de l'utilisateur une attention suffisante sur la saisie de la fiche, qui était considérée comme peu importante au moment du passage en caisse du client.
La version suivante a permis de résoudre ce problème et quelques autres plus mineurs par une conception différente de l'écran de saisie (Figure VII.2.7). Tout d'abord le choix d'une police de caractère originale, des attributs graphiques remaniés et une organisation plus attrayante de l'écran ont pour objectif d'attirer l'attention sur l'écran afin de permettre un minimum de concentration lors de la saisie. Certains attributs tels que la date du jour ont été mis en valeurs car il s'avéraient utiles à consulter (par exemple la date du jour aide les clients à remplir les chèques). Le libellé "réduction" a été supprimé et remplacé par le symbole '%', afin de ne pas tenter inutilement la clientèle qui jetterait un regard sur l'écran.

Figure VII.2.7 : Écran de saisie remanié
La saisie est ralentie par le passage obligatoire du clavier pour saisir le nom à la souris pour saisir les différents services effectués. Le ralentissement n'est pas gênant car les règlements ne se succèdent pas trop rapidement. Les actions sont totalement séquentialisées, pour renforcer la nécessité d'attention : il est nécessaire de désigner d'abord l'exécutant puis le service pour chaque service effectué dans le salon de coiffure.
Nous nous attendions à un accueil mitigé de la part des utilisateurs, la saisie étant fortement contrainte et ralentie. Au contraire, il semblerait que le simple attrait graphique rajouté et l'utilisation plus importante de la souris comme méthode de saisie ait suffit à rendre les utilisateurs réels plus satisfaits de l'interface. Nous constatons dans cet exemple un certain nombre de dérogations à nos règles de conception, qui sont justifiés par le fait que lors de l'utilisation du système, celui-ci n'est pas le focus d'attention principal de l'utilisateur : la relation commerciale est en effet plus important que la saisie.
La prise en compte du contexte d'utilisation intervient également dans la liaison avec le modèle conceptuel, que nous présentons maintenant.
Nous présentons tout d'abord une vue générale d'un système interactif montrant l'interdépendance des modules fonctionnels entre eux, et la nécessité de la prise en compte du système global pour une insertion adaptée de nouvelles fonctionnalités et leurs techniques d'interaction. Puis nous justifions notre approche orientée objets de préférence à une système de types abstrait
La création d'une application ne se fait plus indépendamment d'un environnement. Le travail du concepteur se spécialise dans l'apport de fonctionnalités limitées et précises dans un système à l'architecture déterminée extérieurement. Les applications actuelles ne se présentent pas sous la forme d'un noyau fonctionnel et d'une interface, mais comme un ensemble de modules de fonctionnalités, éventuellement partagés avec d'autres applications. L'interaction est prise en charge partiellement par ces modules de fonctionnalités, pour la partie "interface de données", et en partie également par le module de navigation (système de fenêtrage). En conséquence, le développement d'un nouvel outil interactif consiste essentiellement à proposer un assemblage de modules adaptés à un certain type d'objets. Suivant le modèle d'architecture PAC, le concepteur d'application défini essentiellement un module de contrôle liant diverses fonctionnalités proposées par le système, et ajoute quelques modules spécifiques concernant l'interaction ou le traitement des données.
Nous présentons notre vision d'un système informatique interactif suivant le schéma VII.3.1 :
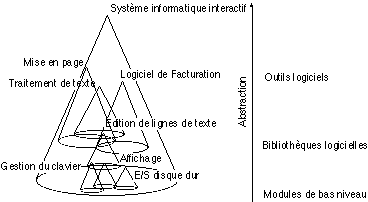
Figure VII.3.1 : modèle d'architecture d'un système interactif avec quelques modules de différents niveaux d'abstraction. Chaque module (présenté sous la forme d'un cône) est une hiérarchie d'agents.
L'axe vertical représente le niveau d'abstraction. Les modules de bas niveau (traitement des entrées/sorties, interface réseau, clavier, présentation, disque, gestion de la mémoire...) sont utilisés indirectement par toutes les applications ou presque. Au niveau intermédiaire se trouvent les bibliothèques ou boîtes à outils offrant certaines fonctionnalités de plus haut niveau (gestion de base de données, gestion et structuration de l'affichage, modules de calcul numérique...). Enfin, les sommets de chaque cône constituent le "concept" d'une application, reposant sur plusieurs modules intermédiaires structurant les modules d'outils en un modèle conceptuel adapté à une utilisation particulière du système.
On notera que plusieurs applications (comme un traitement de texte, un système de gestion de facturation, un système de PAO) peuvent se partager des modules, présentant une intersection non-vide. Par exemple, la gestion de la facturation peut utiliser le traitement de texte pour la saisie des lettres de relance. Cette forme de présentation ne remet pas en cause les modèles d'architecture existants, mais permet de les intégrer dans le cadre plus général du système interactif, qui est formé d'un ensemble d'applications interagissantes et non d'une entité "fonctionnelle" et une entité "interface".
Nous avons précisé dans notre introduction que pour les modèles d'interaction que nous souhaitions étudier, essentiellement orientés vers des tâches dites créatives, il n'est pas toujours possible de définir avec précision les tâches que doit effectuer l'utilisateur au moyen du système. La notion de commande suppose que l'utilisateur réalise des échanges dont la structure est connue et prédéterminée, ce qui n'est pas adapté à toutes les actions de manipulation d'information. Elle impose une structuration fonctionnelle (décrivant "ce qui doit être fait", plutôt que "ce qui est") du modèle d'interaction qui n'est pas appropriée pour des activités "créatives" comme le dessin ou l'exploration d'espaces informationnels, dans lesquelles la tâche est floue car le but de l'utilisateur n'est pas défini a priori.
Aussi, nous préférons représenter le modèle conceptuel suivant un paradigme centré sur les objets du système, plutôt que sur l'activité de l'utilisateur avec ces objets. En effet, même lorsque la tâche ou l'activité effectuée est difficilement caractérisable, les objets manipulés peuvent être décrits précisément. Par exemple, il est difficile de définir en quoi consiste la tâche d'écriture d'une lettre. En revanche, le contenu d'une lettre : entête, adresse, corps, post-scriptum... peut être précisément structuré et défini.
On considérera donc que les actions du langage ne sont pas associées à des opérations (sur des types), mais à des valeurs d'objets. Toute action de l'utilisateur a pour effet de modifier un ou plusieurs objets du modèle conceptuel, suivant un paradigme de manipulation, par opposition à un paradigme linguistique qui représenterai une action par une opération. Les relations entre objets et les opérations sont alors représentées comme un système de contraintes entre les objets : toute modification d'une valeur est susceptible d'entraîner la modification d'autres valeurs suivant la sémantique définie par le concepteur du système. L'application est représentée comme un système réactif sensible aux actions de l'utilisateur, et éventuellement à celles d'autres programmes connectés à des valeurs actives de la partie fonctionnelle de l'application.
Cette approche n'est pas nouvelle : depuis Thinglab [Mahoney, et al. 1989], la programmation par contraintes a connu un essor important et est devenue un domaine de recherche à part entière, même si encore peu d'applications utilisent ce paradigme de représentation. La raison la plus souvent invoquée est que les systèmes de contraintes se prêtent mal à la modularisation, et deviennent très vite complexes et difficiles à contrôler dans le cadre d'applications réelles. Dans notre cas, nous ne nous intéressons pas à la construction de systèmes réels, mais uniquement à la possibilité de les modéliser d'une façon commode pour établir la relation de sémantique. Il nous suffit donc de savoir qu'il est possible de construire un modèle de calcul Turing-complet à partir d'un système de contraintes.
Nous représentons donc notre modèle conceptuel sous la forme d'un système d'objets dont les attributs sont des "slots" au sens employé dans les langages à base de prototypes tel que Self [Ungar et Smith 1987], ou des valeurs actives : toute modification d'un ou plusieurs attributs peut entraîner la résolution de contraintes, c'est à dire la réalisation d'opérations définissant la sémantique de l'application. Par exemple, un objet "dessin" est constitué d'une liste d'objets graphiques. Chaque objet graphique est lui même constitué d'un type et d'une liste de coordonnées. Une action de l'utilisateur se traduira par la modification d'une ou plusieurs de ces coordonnées ; cette modification entraînera la résolution d'une contrainte liée à l'affichage, qui rafraîchira le dessin présenté.
L'utilisation de contraintes pour la représentation des fonctionnalités de l'application n'impose pas pour autant une implantation au moyen d'un langage de prototype. Les contraintes peuvent être présentées sous une forme procédurale. La toolkit X, dans son esprit de base respecte cette approche de mise en oeuvre : les éléments de bases sont des "widgets", objets d'interaction, liés entre eux et avec l'application au moyen de "callbacks", ou procédures de liaison, dont le rôle primordial est de définir les relations entre les objets du système interactif. Plus évolué est le mécanisme de valeur observée/observateur d'Interviews et de son successeur Fresco [Linton 1994]. Celui-ci se révèle très commode pour implanter la multimodalité actionnelle : les événements captés sont distribués en fonction de leur type et de leur caractéristiques à des objets "sensibles". La séparation des canaux d'interaction (main dominante/main non dominante) et la propagation des événements de bas niveau vers les fonctionnalités de l'application est ainsi traitée suivant un mécanisme uniforme et aisément extensible. Ce mécanisme est utilisé avec succès dans le logiciel StudioPaint [Alias|Wavefront 1995] pour implanter des techniques d'interaction à deux mains.
Le mécanisme de contraintes unidirectionnelles de Garnet [Myers, et al. 1990] a une fonction similaire. Enfin, des mécanismes plus évolués comme les algorithmes de résolution Delta-Blue [Freeman-Benson 1988] ou Alien [Cournarie 1991] permettent une expression de la sémantique sous une forme non procédurale. Cependant, ces moteurs de résolution de contraintes ne sont pas conçus à l'origine pour la structuration de l'interaction, mais plutôt celle de la présentation.
Si plusieurs objets ont une même image par S, cela signifiera que ces objets sont modifiés par la même action, c'est à dire que l'action est intégrale (au sens de R. Jacob). Par exemple le déplacement du curseur modifie à la fois l'abscisse et l'ordonnée du pointeur figuré sur l'écran : il n'est pas possible de séparer la spécification de l'ordonnée de celle de l'abscisse d'un point désigné à l'écran dans les modèles d'interaction courants. Les attributs X et Y de la position du curseur dans le modèle conceptuel sont associé à la même action élémentaire "déplacement de la souris".
Ainsi, l'orientation de la relation de sémantique (application de C vers L(Ai)) se justifie : une fois déterminés les attributs modifiables par l'utilisateur et après les avoir groupés en valeurs séparables et non séparables, il convient de déterminer l'image de chacun des objets, c'est à dire l'action permettant lui faire prendre une valeur différente.
Cette démarche permet de construire un modèle d'interaction abstrait, puisque indépendant de la forme considérée des dispositifs utilisables. Elle permet d'obtenir un aspect a priori de la forme que doivent prendre les actions pour générer une interaction directe et complète. En reprenant l'exemple de notre éditeur de dessin constitué d'objets graphiques, on pourra déterminer les actions permettant de modifier une ou plusieurs coordonnées d'un objet graphique : les actions disponibles doivent permettre de modifier conjointement l'abscisse et l'ordonnée d'une ou plusieurs coordonnées d'un objet. On en déduit la nécessité de fournir une action permettant de modifier de façon intégrale (non-séparable), et préférentiellement de façon continue, les valeurs d'attributs. Un dispositif d'entrée à deux dimensions continues comme une souris ou une tablette parait mieux adapté qu'un clavier. Un objet étant constitué de plusieurs points, il sera sans doute préférable de disposer de plusieurs dispositifs autorisant la manipulation en parallèle de plusieurs des coordonnées de l'objet.
Les expériences de manipulation à deux souris d'objets menées par Stéphane Chatty et à l'université de Toronto et au CENA [Kabbash, et al. 1994], [Chatty 1994] montrent qu'il est possible d'utiliser une telle technique d'interaction, et celle-ci se révèle manifestement plus directe, puisqu'elle évite le changement de mode pour différencier le retaillage d'un objet de son déplacement.
* Définition d'un modèle conceptuel (intersection aura système/nimbus utilisateur) sous forme d'objets et de relations fonctionnelles entre ces objets. Ces relations peuvent être décrites sous la forme d'un système de contraintes ou mises sous formes procédurales. L'ensemble des valeurs d'objets du modèle conceptuel constitue l'ensemble de départ de la relation S. Cette étape débouche sur la construction d'un modèle d'interaction "abstrait" : elle consiste en la description d'un ensemble d'actions abstraites effectuables sur le modèle de données.
* Structuration du modèle conceptuel C, par la mise en évidence des valeurs séparables et intégrales, et définition du langage L(Ai). Cette mise en forme nous permet de déterminer la structure de la relation S et les propriétés de l'ensemble image L(Ai) : les objets auront une image d'autant plus "proche" par la relation S transformée en application qu'ils sont intégralement liés. Il est ainsi possible de hiérarchiser l'espace image en classes regroupant les valeurs liées ou "presque liées" ensemble. Cette étape fournit certaines des règles du langage L(Ai) : les valeurs liées seront accessibles à partir du même mode, tandis que les valeurs nettement séparables pourront être accédés à partir de phrases du langage à la structure différente (par l'introduction de modes). Il peut être nécessaire à ce moment d'introduire des actions supplémentaires de changement de modes (interface de contrôle), mettant en relief la structure du modèle conceptuel et permettant de conserver au vocabulaire d'action une taille raisonnable.
* Définition du vocabulaire d'actions élémentaires (souhaitables/disponibles) en fonction de la forme du langage souhaité, des dispositifs et action disponibles technologiquement, de l'acquis (système à utiliser), de l'utilisateur, des contraintes externes... Cette étape utilise les règles que nous avons décrites au chapitre VII.2 pour déterminer un vocabulaire concis, naturel et adapté.
Le modèle conceptuel que manipule l'utilisateur est un dessin, que nous présentons comme un ensemble de traits. Cette définition est certes restrictive par rapport à la façon dont l'artiste peut percevoir un dessin au sens général, elle ne prend notamment pas en compte la notion de forme. Cependant, la perception d'un ensemble de traits peut suffire à de nombreuses techniques graphiques utilisables. C'est vers l'utilisation de ces techniques que s'oriente Ligne Claire. La représentation interne de chaque trait est une fonction paramétrique de deux variables, ou encore une trajectoire échantillonnée et lissée. Cette représentation n'a cependant pas à être perçue par l'utilisateur en tant que telle. Pour modifier un dessin existant (qui peut être le dessin vide), l'utilisateur peut ajouter un trait au dessin, modifier un trait existant, en supprimer tout ou portion ou joindre deux traits existants. Ces actions constituent le "vocabulaire abstrait" du modèle d'interaction.
Ce vocabulaire abstrait permet de définir le langage de base, constitué de quatre types d'actions principales : création d'une courbe, modification, suppression (partielle ou complète) et jointure. Il est sans doute possible de distinguer ces actions en fonction de la forme des gestes effectués et le contexte (la suppression étant détectée par une trajectoire "raturée", la jointure en fonction du contexte du tracé, la modification détectée par la proximité d'une courbe à modifier). Cependant nous avons choisi d'éviter tout risque d'ambiguïté et d'expliciter l'intention d'action par l'état du clavier : aucune touche enfoncée indique la création d'une courbe, la touche espace la modification... Il est à noter que cette explicitation de l'intention n'est pas introduite par des modes. En effet, on pourra considérer l'appui (avec maintien) sur une touche du clavier et la spécification de la valeur (courbe modificatrice) comme une seule action élémentaire.
Les actions élémentaires sont détaillées comme suit :
* La création d'un trait requiert la donnée d'une trajectoire en 2 dimensions. Pour cela, l'utilisation d'une tablette graphique échantillonnant les tracés de l'utilisateurs parait la méthode la plus directe, la plus naturelle et la plus concise.
* La modification d'un trait existant requiert l'expression de la différence entre l'objet de départ et d'arrivée. L'idée essentielle de Ligne Claire est de permettre l'expression de cette différence par la seule spécification de la portion de trajectoire modifiée. La position de la trajectoire modifiée suffit à exprimer l'objet à modifier et les valeurs à transformer. Ainsi, la technique d'interaction repose sur l'entrée de la seule différence entre l'état de départ et l'état d'arrivée. Cette technique est donc concise. Elle s'inspire des techniques couramment usitées de dessin, ce qui lui confère un certain naturel.
* La suppression et la jointure sont issues du même principe de spécification conjointe de l'objet à modifier et de la nouvelle valeur à introduire.
Enfin, une fois les actions élémentaires totalement explicitées, il reste à déterminer les aspects pragmatiques de l'interaction, et notamment à préciser que l'entrée d'une courbe avec suffisamment de précision ne peut se faire qu'au moyen d'une tablette graphique. L'étude de l'utilisation effective par des graphistes nous montre également l'importance d'un écho sémantique (préservation des modifications successives d'un trait sur une certaine période).
La présentation de cet exemple demeure assez schématique : dans la pratique, la mise au point d'un tel modèle d'interaction se fait de façon itérative, et il est peu probable qu'une analyse descendante telle que nous l'avons pratiquée aboutisse immédiatement à un modèle d'interaction tel que Ligne Claire. Ces grandes lignes doivent surtout permettre d'établir la relation entre les étapes que nous avons décrites et une mise en oeuvre pratique.
Nous avons exhibé les différentes étapes de la construction d'un modèle d'interaction, en distinguant le cadre général, qui se prête à une formalisation, tandis que plusieurs étapes font appel à un savoir-faire que nous ne savons incorporer dans une méthode formelle. Cette démarche présente certaines limites. Elle ne prend en compte que l'étude des entrées intentionnelles de l'utilisateur dans le système. De plus, nous ne nous sommes pas attachés à définir un cadre parfaitement rigoureux et précis : il nous appartient maintenant de raffiner notre analyse, de vérifier qu'elle est applicable à d'autres exemples que ceux qui nous ont permis de la construire.